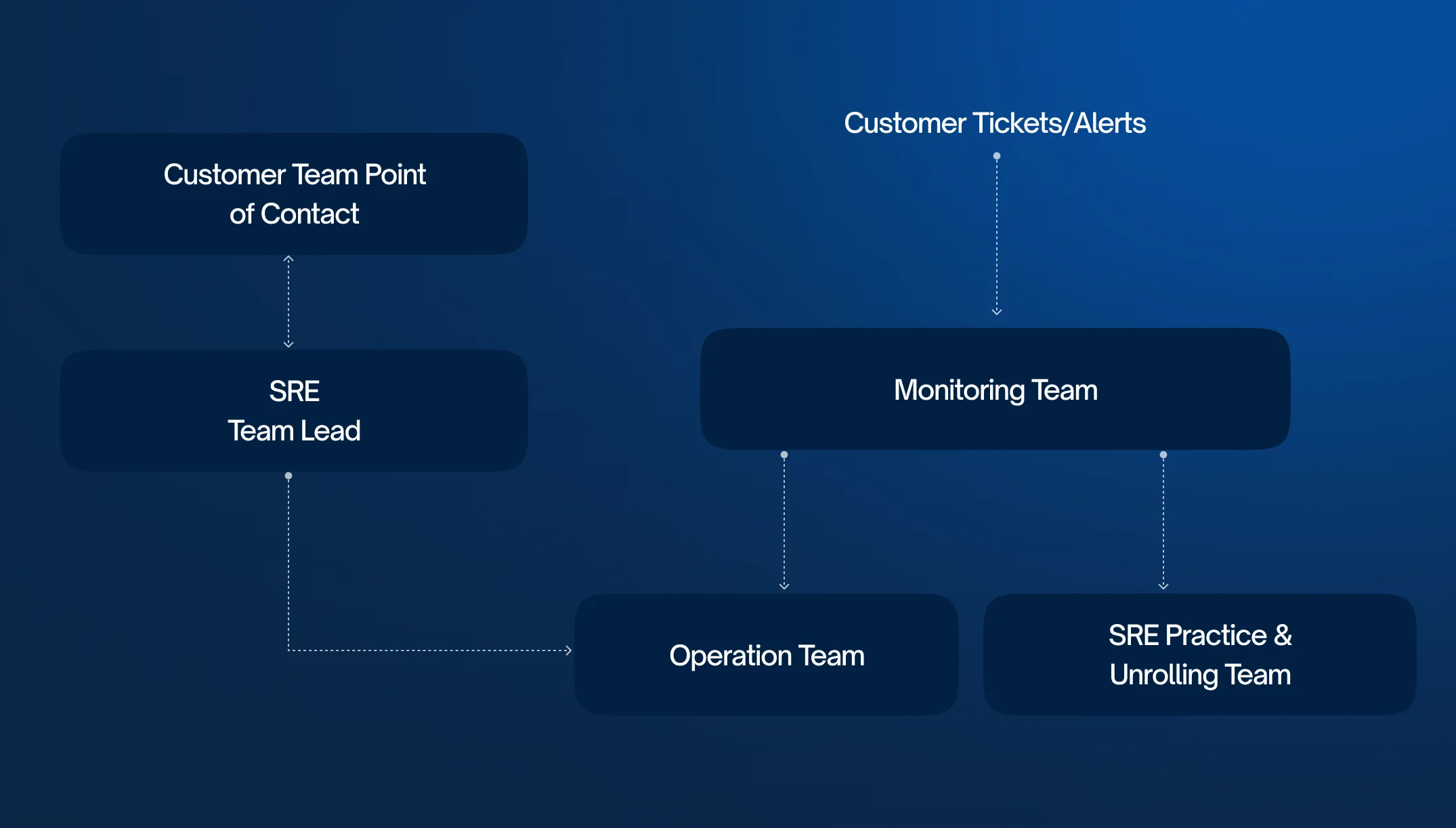
Ensure Uptime, Improve Resilience, Operate With Confidence
Round-the-clock monitoring, alerting, and incident response from expert SREs who treat your infrastructure like their own.
01
Discovery & Monitoring Setup
Assess existing systems and integrate observability tools across infrastructure and applications.
02
Alerting & Runbook Creation
Build intelligent alerts with well-defined escalation paths and clear documentation for faster response.
03
24/7 Coverage Activation
Deploy a global SRE team with round-the-clock coverage and real-time dashboards.
04
Continuous Optimization
Identify reliability gaps and optimize systems for performance, cost, and availability.
Our Core Solutions
Current Architecture Review & Assessment
Every reliability journey begins with understanding where you are today.
- Detailed architecture and infrastructure review
- Dependency mapping and system flow diagrams
- Incident history and downtime analysis
What we use
- Reliability assessment report with key gaps
- Monitoring and observability maturity check
- Risk and bottleneck identification plan
What we implement
- A clear baseline of system strengths and weaknesses
- Early identification of high-risk areas before failures occur
- Foundation for building a 24/7 reliability strategy
How it helps you
24/7 Monitoring & Alerting

Proactive monitoring prevents small issues from turning into outages.
- Prometheus, Grafana, ELK Stack, Loki
- Cloud monitoring tools (AWS CloudWatch, Azure Monitor, GCP Ops)
- PagerDuty, Opsgenie for on-call and escalation
What we use
- Centralized monitoring dashboards
- Automated alerts with priority-based escalation
- Real-time observability pipelines across infrastructure, applications, and logs
What we implement
- Issues detected before customers notice them
- Faster reaction to outages with clear escalation paths
- True peace of mind knowing your systems are always watched
How it helps you
Incident & Problem Management
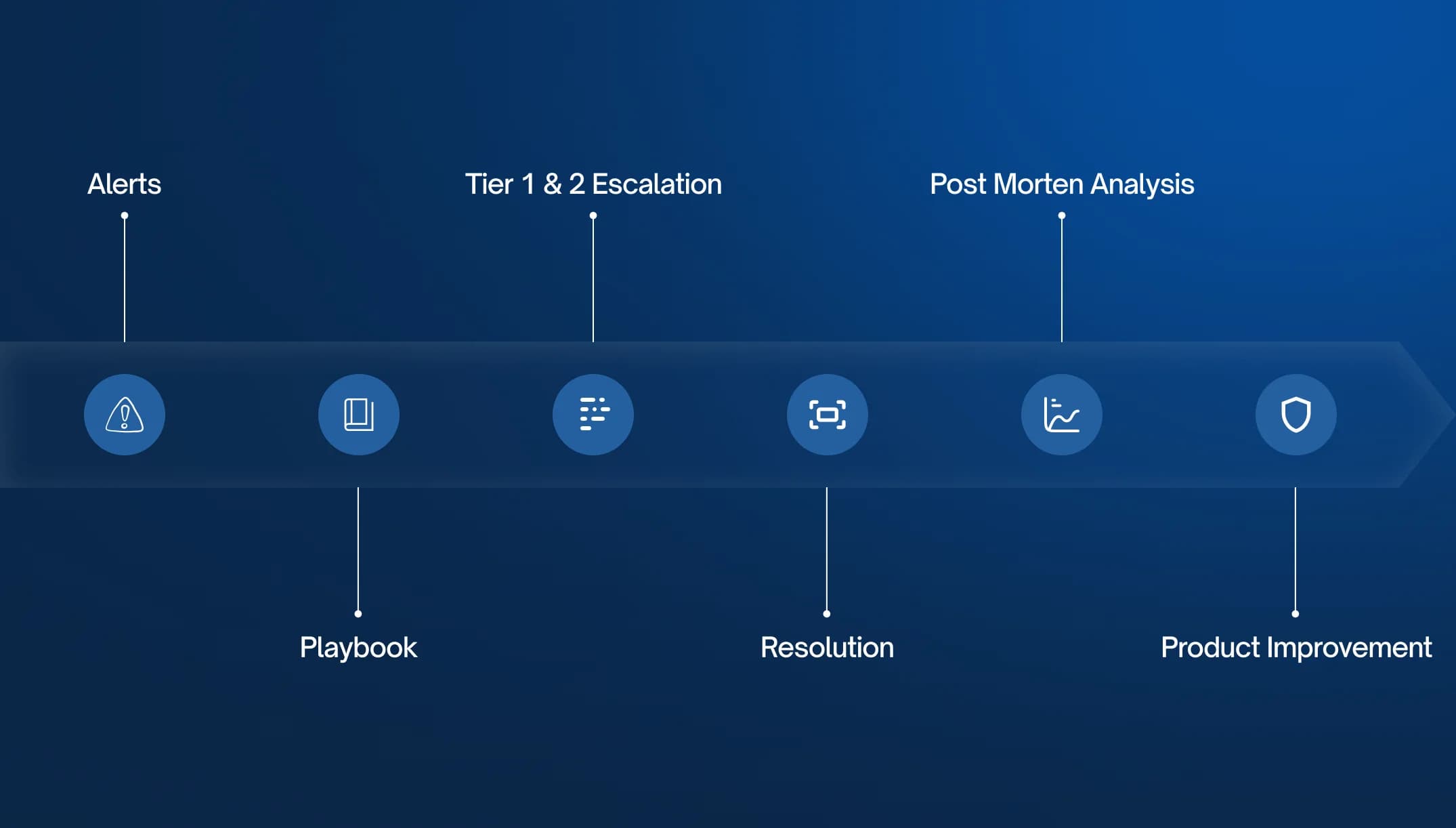
We ensure incidents are handled fast and root causes are permanently addressed.
- ITSM tools like ServiceNow, Jira Service Management
- Standardized runbooks and playbooks
What we use
- SLA-driven incident response processes
- Post-incident reviews and action items
- Knowledge base to reduce repeat issues
What we implement
- Lower Mean Time to Recovery (MTTR)
- Fewer recurring incidents
- Stronger operational discipline and resilience
How it helps you
Continuous Reporting & Improvement

Reliability is a journey that requires ongoing visibility and optimization.
- Cost-performance optimization frameworks
- Weekly and monthly review templates
What we use
- Regular reviews of error budgets and system health
- Continuous roadmap for improvements
What we implement
- Systems that keep getting better over time
How it helps you
Benefits of 24/7 SRE Support
Ensure Continuous Availability
Modern businesses demand systems that are always on. With 24/7 Site Reliability.
Proactive Incident Response
SREs don’t just react—they monitor, detect anomalies early, and resolve issues before users are affected.
Maintain Performance
As your traffic grows, so do your reliability needs. 24/7 SRE practices help optimize performance.
Automate And Improve Continuously
SRE engineers implement automation for repetitive tasks, enabling teams to focus on innovation.
Success Stories

Enterprise Kubernetes Monitoring with Self-Hosted Grafana | AWS
Read More
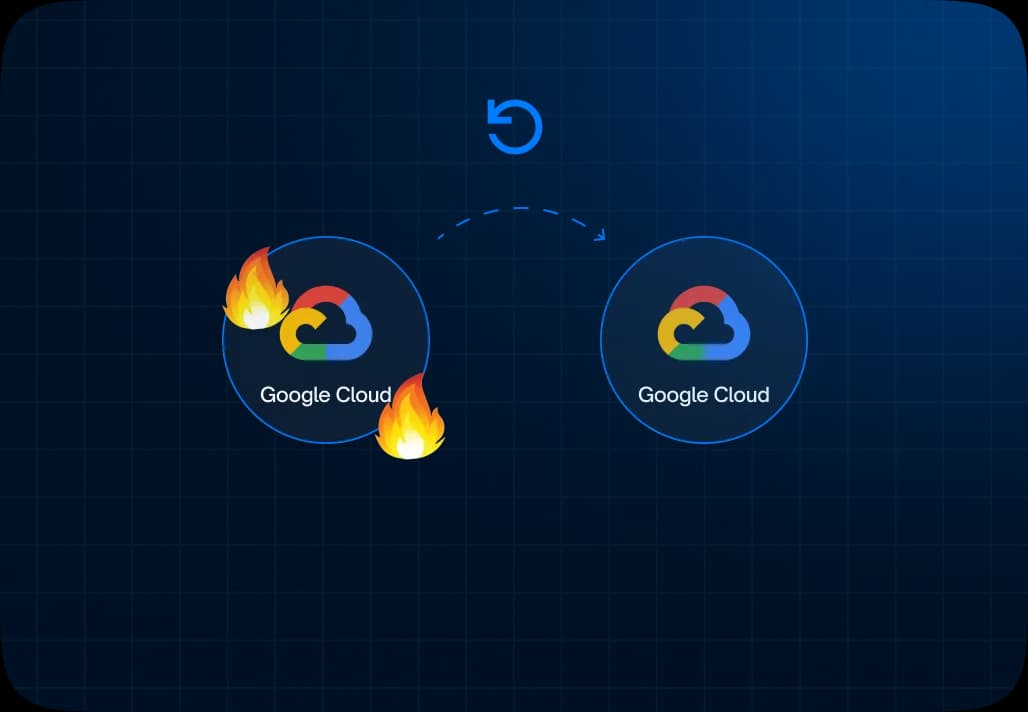
Enabling Seamless Disaster Recovery with 100% Availability on GCP
Read More
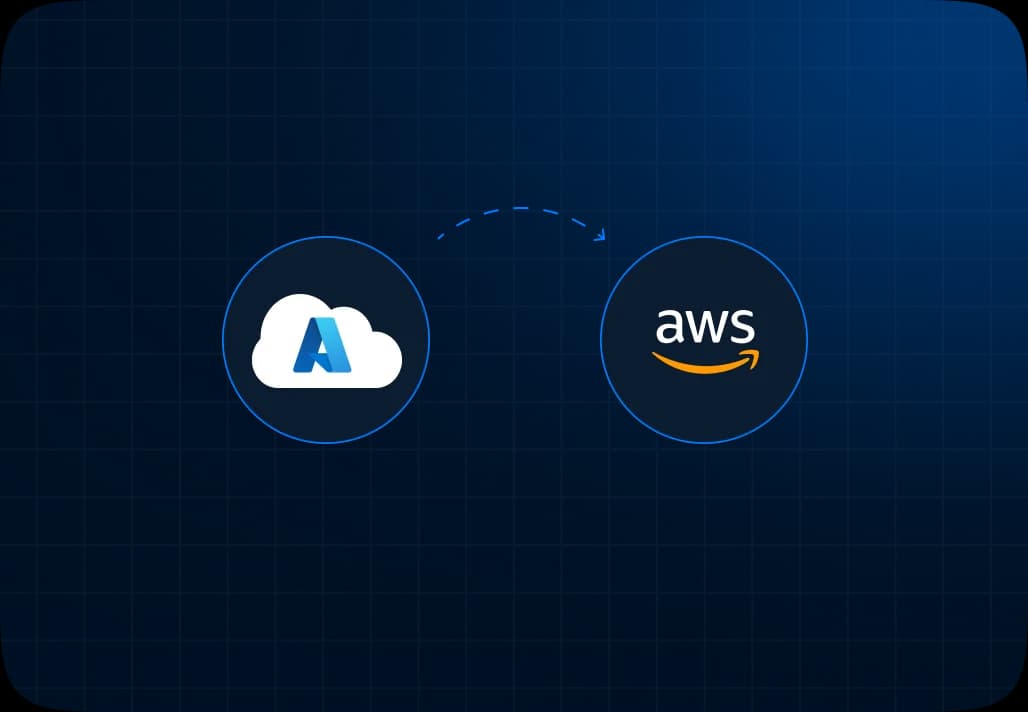
Simplified AWS Migration for Better Performance and Lower Costs
Read More
Ready To Scale Smarter?
Talk to our experts and discover how CloudArcOps can improve your infrastructure and save costs.
Choose a time that works for you. No pressure, just ideas.
Book a Call
Contact Us